人工智能:一种现代的方法 书本课后习题解答
文章目录摘要更新:课本及习题答案下载第一章——绪论1.1用自己的语言定义(1)智能,(2)人工智能,(3)Agent,(4)理性,(5)逻辑推理。1.2反射行动(如从热炉子上缩手)是理性的嘛?是智能的嘛?第二章——智能Agent2.22.33.第三章3.33.43.53.63.73.83.9找出一个状态空间,使用迭代加深搜索比深度优先搜索的性能要差很多(如,一个是$O(n^2)$,另一个是O(n))。3.10第四章超越经典搜索4.24.3第五章——对抗搜索5.1对alpha-beta剪枝的理解5.25.3第六章约束满足问题6.1地图着色问题有多少个解?6.26.36.4第七章逻辑Agent7.17.27.37.4第八章一阶逻辑8.18.28.38.48.5第九章——一阶逻辑的推理9.2第十章——经典规划10.1问题求解和规划之间的不同和相似之处10.210.3证明PDDL问题的后向搜索是完备的10.4为什么在规划问题中去掉每个动作模式的负效果会得到一个松弛问题第十一章——现实世界的规划与行动11.1暂无,这一章有点难,我有空再加。第十三章——不确定性的量化13.1贝叶斯规则13.2使用概率公理证明:一个离散随机变量的任何概率分布,总和等于113.313.4第十四章——概率推理资源下载文末诗词参考文献摘要本文旨在呈现《人工智能:一种现代的方法》中的一些经典、有趣的习题。
《人工智能:一种现代的方法》的习题答案可以在我的CSDN资源页下载
更新:课本及习题答案下载第一次写作时间:2018年07月08日21:57:42更新时间:2018年12月3日21:33:05
看到很多网友评论,发现大家对课本及习题答案的需求不小,然而CSDN无法上传这样的资料,所以这里建立一个百度云链接,大家可以自取,祝大家学习进步,考研的同学考研顺利:链接:https://pan.baidu.com/s/19KGXMLv-WVHHfFfpVJ6VnA提取码:eku2
第一章——绪论1.1用自己的语言定义(1)智能,(2)人工智能,(3)Agent,(4)理性,(5)逻辑推理。答:1)Intelligence:theabilitytoapplyknowledgeinordertoperfrombetterinanenvironment.2)Artificialintelligence:thestudyandconstructionofagentprogramsthatperformwellinagivenenvironment,foragivenagentarchitecture.3)Agent:anentitythattakesactioninresponsetoperceptsfromanenvironment.4)理性:thepropertyofasystemwhichdoesthe“rightthing”givenwhatitknows.5)逻辑推理:theaprocessofderivingnewsentencesfromold,suchthatthenewsentencesarenecessarilytrueiftheoldonesaretrue.
1.2反射行动(如从热炉子上缩手)是理性的嘛?是智能的嘛?答:是理性的。becauseslower,deliberativeactionswouldtendtoresultinmoredamagetothehand.不是智能的。If“intelligent”means“applyingknowledge”or“usingthoughtandreasoning”thenitdoesnotrequireintelligencetomakeareflexaction.
第二章——智能Agent###2.1
**图2.1习题2.1**答:1)错。Perfectrationalityreferstotheabilitytomakegooddecisionsgiventhesensorinformationreceived.2)对。纯反射agent忽略之前的感知信息,所以在部分可感知的环境中是不能达到一个最优的状态估计的。Forexample,correspondencechessisplayedbysendingmoves;iftheotherplayer’smoveisthecurrentpercept,areflexagentcouldnotkeeptrackoftheboardstateandwouldhavetorespondto,say,“a4”inthesamewayregardlessofthepositioninwhichitwasplayed.3)对。Forexample,inanenvironmentwithasinglestate,suchthatallactionshavethesamereward,itdoesn’tmatterwhichactionistaken.Moregenerally,anyenvironmentthatisreward-invariantunderpermutationoftheactionswillsatisfythisproperty.4)错。Theagentfunction,notionallyspeaking,takesasinputtheentireperceptsequenceuptothatpoint,whereastheagentprogramtakesthecurrentperceptonly.5)错。Forexample,theenvironmentmaycontainTuringmachinesandinputtapesandtheagent’sjobistosolvethehaltingproblem;thereisanagentfunctionthatspecifiestherightanswers,butnoagentprogramcanimplementit.Anotherexamplewouldbeanagentfunctionthatrequiressolvingintractableprobleminstancesofarbitrarysizeinconstanttime.图灵停机问题参考:[1]
6)对。Thisisaspecialcaseof(3);ifitdoesn’tmatterwhichactionyoutake,selectingrandomlyisrational7)对。Forexample,wecanarbitrarilymodifythepartsoftheenvironmentthatareunreachablebyanyoptimalpolicyaslongastheystayunreachable8)错。Someactionsarestupid—andtheagentmayknowthisifithasamodeloftheenvironment—evenifonecannotperceivetheenvironmentstate.9)错。Unlessitdrawstheperfecthand,theagentcanalwaysloseifanopponenthasbettercards.Thiscanhappenforgameaftergame.Thecorrectstatementisthattheagent’sexpectedwinningsarenonnegative.
2.2**图2.2.1习题2.2****图2.2.2答案2.2**2.3**图2.3.1问题2.3**答:Agent:anentitythatperceivesandacts;Essentiallyanyobjectqualifies;thekeypointisthewaytheobjectimplementsanagentfunction.Agentfunction:afunctionthatspecifiestheagent’sactioninresponsetoeverypossibleperceptsequence.Agentprogram:thatprogramwhich,combinedwithamachinearchitecture,implementsanagentfunction.Inoursimpledesigns,theprogramtakesanewperceptoneachinvocationandreturnsanaction.Rationality:apropertyofagentsthatchooseactionsthatmaximizetheirexpectedutility,giventheperceptstodate.Autonomy:apropertyofagentswhosebehaviorisdeterminedbytheirownexperienceratherthansolelybytheirinitialprogramming.Reflexagent:anagentwhoseactiondependsonlyonthecurrentpercept.Model-basedagent:anagentwhoseactionisderiveddirectlyfromaninternalmodelofthecurrentworldstatethatisupdatedovertime.Model-basedagent:anagentwhoseactionisderiveddirectlyfromaninternalmodelofthecurrentworldstatethatisupdatedovertime.Utility-basedagent:anagentthatselectsactionsthatitbelieveswillmaximizetheexpectedutilityoftheoutcomestate.Learningagent:anagentwhosebehaviorimprovesovertimebasedonitsexperience.
3.第三章###3.1为什么问题的形式化要在目标的形式化之后?答:目标形式化中,我们决定对世界的哪些方面感兴趣这样的话,在问题形式化里面,我们就能直接决定留哪些东西,操作哪些。
###3.2
**图3.2.1问题3.2****图3.2.2答案3.2**之所以记录这个问题,是因为我对这个(b)问题比较感兴趣:有关可采纳函数的判断(不能高估实际花销)。
3.3**图3.3.1问题3.3****图3.3.2答案3.3**记录这个问题,因为它的推导很巧妙,很有意思,而且非常之详细,让人不禁生出记录称赞的想法。
###3.4野人和传教士问题和3.2的形式化问题差不多。多了一个:要检查重复状态的操作。具体答案+代码在[2]
3.4**图3.4.1问题3.4**答:state状态:Astateisasituationthatanagentcanfinditselfin.Wedistinguishtwotypesofstates:worldstates(theactualconcretesituationsintherealworld)andrepresentationalstates(theabstractdescriptionsoftherealworldthatareusedbytheagentindeliberatingaboutwhattodo)statespace状态空间:Astatespaceisagraphwhosenodesarethesetofallstates,andwhoselinksareactionsthattransformonestateintoanothersearchtree搜索树:isatree(agraphwithnoundirectedloops)inwhichtherootnodeisthestartstateandthesetofchildrenforeachnodeconsistsofthestatesreachablebytakinganyaction.searchnode搜索节点:isanodeinthesearchtree.goal目标:astatethattheagentistryingtoreachaction行动:somethingthattheagentcanchoosetodo.successorfunction后继函数:asuccessorfunctiondescribedtheagent’soptions:givenastate,itreturnsasetof(action,state)pairs,whereeachstateisthestatereachablebytakingtheaction.**branchingfactor分支因子**:Thebranchingfactorinasearchtreeisthenumberofactionsavailabletotheagent
3.5**图3.5.1问题3.5****图3.5.2答案3.5**这道题有一个很有意思的想法:抛弃序列结构(压扁状态空间),即把一些动作都组合起来,变成一个超级行动。这样的话整个搜索树深度为1.
坏处,如果发现Go中的第一个行动(unplugyourbattery)不是解,很难把后面也含这个行动的整合行动给排除掉。
3.6**图3.6.1问题3.6****图3.6.2答案3.6**这些判断题也很有意思,但是答案的(c)应该是false。作者写错了。
3.7**图3.7.1问题3.7****图3.7.2答案3.7**3.8**图3.8.1问题3.8****图3.8.2答案3.8**为什么要放这道题?因为答案有错误的地方,状态空间应该是n2∗2n2n^2*2^{n^2}n2∗2n2
3.9找出一个状态空间,使用迭代加深搜索比深度优先搜索的性能要差很多(如,一个是O(n2)O(n^2)O(n2),另一个是O(n))。答:Consideradomaininwhicheverystatehasasinglesuccessor,andthereisasinglegoalatdepthn.Thendepth-firstsearchwillfindthegoalinnsteps,whereasiterativedeepeningsearchwilltake1+2+3+···+n=O(n2)O(n^2)O(n2)steps
3.10**图3.10.1问题3.10****图3.10.2答案3.10**第四章超越经典搜索###4.1在不确定、部分可观察的环境中,Agent怎么达成目标?答:在完全可观察的、确定的环境下,Agent可以准确地计算出经过任何行动序列之后能达到什么状态,Agent总是知道自己处于什么状态,其传感器一开始告知agent初始状态,而在行动之后无需提供新的信息。如果部分可观察、不确定,感知信息就变得非常有用了。部分可观察:每个感知信息都可能缩小Agent可能的状态范围,这样也就使得Agent更容易达到目标。环境不确定:感知信息告诉Agent某一行动的结果到底是什么。
在这两种情况中。问题的解不是一个序列(因为没法预知未来信息,Agent的未来行动依赖于未来感知信息),而是一个应急规划(也叫:策略)
应急规划描述了根据接收到的感知信息来决定行动。
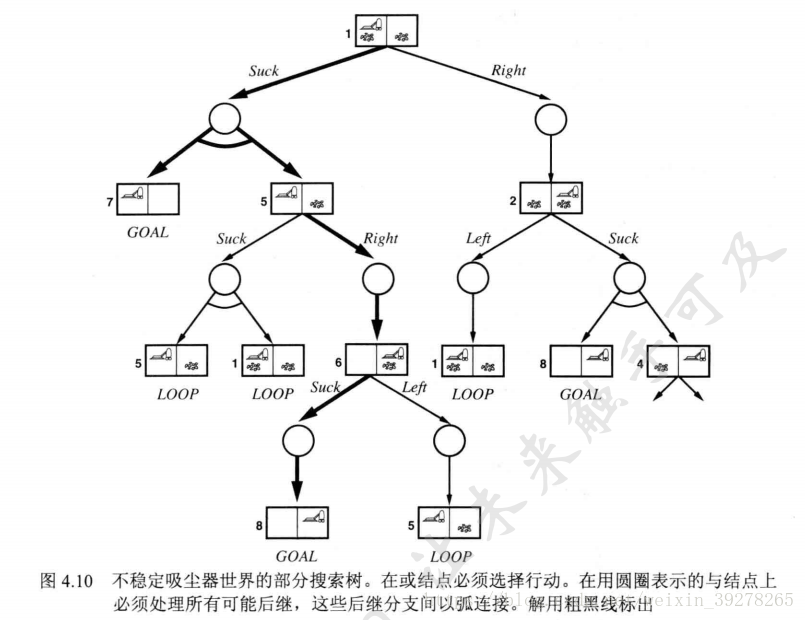**图4.1与或图搜索**在图中,在或节点给行动,与节点考虑所有后继。
4.2**图4.2.1问题4.2**答案:a)爬山法b)宽度优先。Localbeamsearchwithoneinitialstateandnolimitonthenumberofstatesretained,resemblesbreadth-firstsearchinthatitaddsonecompletelayerofnodesbeforeaddingthenextlayer.Startingfromonestate,thealgorithmwouldbeessentiallyidenticaltobreadth-firstsearchexceptthateachlayerisgeneratedallatonce.c)SimulatedannealingwithT=0atalltimes:ignoringthefactthattheterminationstepwouldbetriggeredimmediately,thesearchwouldbeidenticaltofirst-choicehillclimbingbecauseeverydownwardsuccessorwouldberejectedwithprobability1.(Exercisemaybemodifiedinfutureprintings.)d)SimulatedannealingwithT=∞atalltimesisarandom-walksearch:italwaysacceptsanewstate.e)GeneticalgorithmwithpopulationsizeN=1:ifthepopulationsizeis1,thenthetwoselectedparentswillbethesameindividual;crossoveryieldsanexactcopyoftheindividual;thenthereisasmallchanceofmutation.Thus,thealgorithmexecutesarandomwalkinthespaceofindividuals.
4.3**图4.3.1问题4.3****图4.3.2答案4.3**###4.4用局部搜索中的爬山法求解TSP问题答:·Connectallthecitiesintoanarbitrarypath.·Picktwopointsalongthepathatrandom.·Splitthepathatthosepoints,producingthreepieces.·Tryallsixpossiblewaystoconnectthethreepieces.·Keepthebestone,andreconnectthepathaccordingly.·Iteratethestepsaboveuntilnoimprovementisobservedforawhile.
第五章——对抗搜索5.1对alpha-beta剪枝的理解参考[3](提出了一个下界,钳制值的观点,我觉得比较有意思)
但是主要还是要参考书本上的例子和算法(伪代码),照着算法和例子走一遍程序就比较好理解了。
5.2**图1问题5.2****图2答案5.2-部分**两个八数码问题。形式化该问题:1)初始状态:两个随机地8数码2)后继函数:在一个未解决的puzzle上做移动3)目标测试:两个问题都达到目标状态4)cost移动步数。
这里有必要介绍一下八数码的状态空间[4]
对于八数码问题的解决,首先要考虑是否有答案。每一个状态可认为是一个1×9的矩阵,问题即通过矩阵的变换,是否可以变换为目标状态对应的矩阵?由数学知识可知,可计算这两个有序数列的逆序值,如果两者都是偶数或奇数,则可通过变换到达,否则,这两个状态不可达。这样,就可以在具体解决问题之前判断出问题是否可解,从而可以避免不必要的搜索。如果初始状态可以到达目标状态,那么采取什么样的方法呢?常用的状态空间搜索有深度优先和广度优先。广度优先是从初始状态一层一层向下找,直到找到目标为止。深度优先是按照一定的顺序前查找完一个分支,再查找另一个分支,以至找到目标为止。广度和深度优先搜索有一个很大的缺陷就是他们都是在一个给定的状态空间中穷举。这在状态空间不大的情况下是很合适的算法,可是当状态空间十分大,且不预测的情况下就不可取了。他的效率实在太低,甚至不可完成。由于八数码问题状态空间共有9!个状态,对于八数码问题如果选定了初始状态和目标状态,有9!/2个状态要搜索,考虑到时间和空间的限制,在这里采用A*算法作为搜索策略。在这里就要用到启发式搜索
5.3**图1问题5.3-部分****图2答案5.3-部分**这个问题也比较经典,所以在这里记录了。
第六章约束满足问题6.1地图着色问题有多少个解?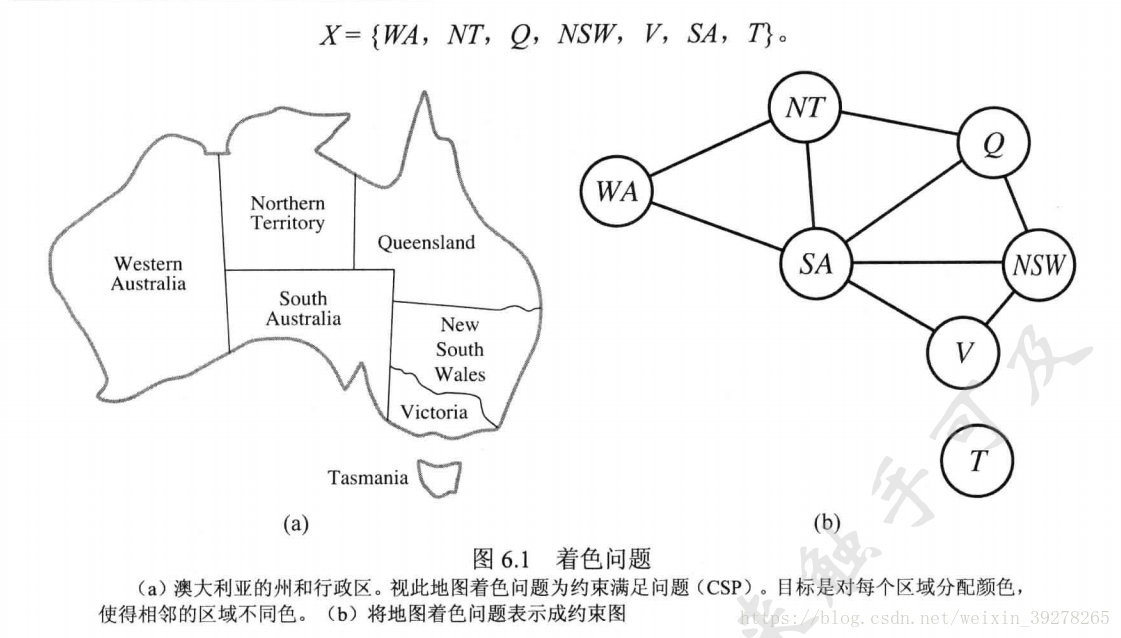**图1问题6.1**这个用度启发式,先找到SA,后面的就好取了。3*2*3=18个解。6.2**图1问题6.2****图2答案6.2**这道题有点像八皇后的变形,答案给了A,B两种解法,都很有意思的。
6.3**图1问题6.3****图2答案6.3**有时候感觉类比过来很麻烦啊,根本想不到。想不通。不是那么简单明了
这道题的(c)我没看懂。记录之。
6.4**图1问题6.4**答:这道题的答案给出了两种CSP的形式化定义。1)25个变量,5个颜色,5个宠物,5个国家,5种饮料,5种香烟。值就是对应的房间号。2)5个变量,5个房间。值域就是每个房间对应的5个属性。
第七章逻辑Agent7.1**图1问题7.1**答案:只要KB为真的时候,两个语句为真,那么就是真。
7.2**图1问题7.2**之所以列出这个问题,是希望举一反三,用7.1的方法罗列出所有世界模型即可。
7.3**图1问题7.3****图2答案7.3**基本功题目。转成CNF。
7.4**图1问题7.4****图2答案7.4**这道题也比较基础吧,记录一下。
第八章一阶逻辑8.1**图1问题8.1****图2答案8.1**8.2**图1问题8.2****图2答案8.2**一阶逻辑推理。
8.3**图1问题8.3****图2答案8.3**用一阶逻辑表示。
8.4**图1问题8.4****图2答案8.4**比较有趣的一个逻辑推理吧。
8.5**图1问题8.5****图2答案8.5**最后一问有些难。
第九章——一阶逻辑的推理###9.1什么是前向链接?从知识库KB中的原子语句出发,在前向推理中应用假言推理规则,增加新的原子语句,直到不能进行任何推理。
9.2**图1问题9.2****图2答案9.2**一个存在量词的代换。第十章——经典规划10.1问题求解和规划之间的不同和相似之处相同:Gettingfromastartstatetoagoalusingasetofdefinedoperationsoractions,typicallyinadeterministic,discrete,observableenvironmnet.不同:Inplanning,however,weopenuptherepresentationofstates,goals,andplans,whichallowsforawidervarietyofalgorithmsthatdecomposethesearchspace,searchforwardsorbackwards,anduseautomatedgenerationofheuristicfunctions.
10.2**图1问题10.2****图2答案10.2**10.3证明PDDL问题的后向搜索是完备的答:Briefly,thereasonisthesameasforforwardsearch:intheabsenceoffunctionsymbols,aPDDLstatespaceisfinite.HenceanycompletesearchalgorithmwillbecompleteforPDDLplanning,whetherforwardorbackward
10.4为什么在规划问题中去掉每个动作模式的负效果会得到一个松弛问题答:Goalsandpreconditionscanonlybepositiveliterals.Soanegativeeffectcanonlymakeithardertoachieveagoal(orapreconditiontoanactionthatachievesthegoal).Therefore,eliminatingallnegativeeffectsonlymakesaproblemeasier.Thiswouldnotbetrueifnegativepreconditionsandgoalswereallowed.
第十一章——现实世界的规划与行动11.1暂无,这一章有点难,我有空再加。第十三章——不确定性的量化13.1贝叶斯规则**图1答案13.1**13.2使用概率公理证明:一个离散随机变量的任何概率分布,总和等于1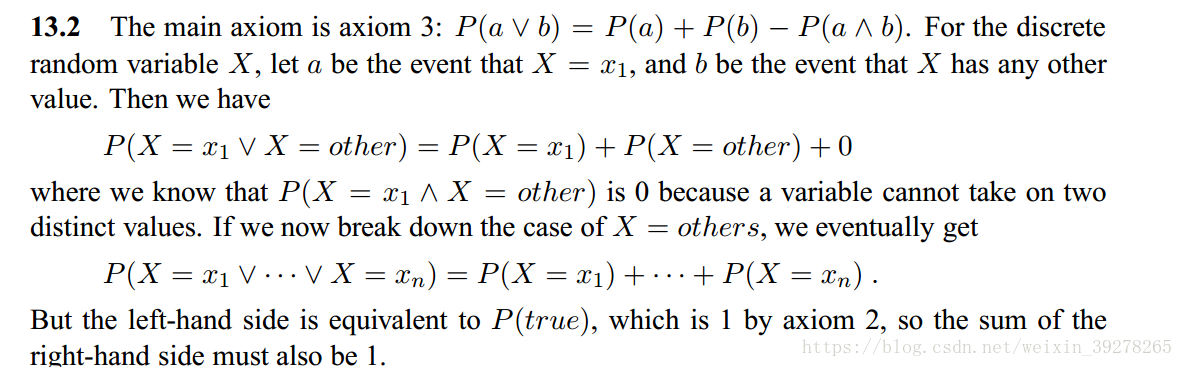**图1答案13.2**我觉得这道题还有有意思的,这里记录一下。
13.3**图1问题13.3****图2答案13.3**13.4**图1问题13.4****图2答案13.4**一个文本分类的简单变形。
第十四章——概率推理###14.1
**图1问题14.1****图2答案14.1**资源下载如果想浏览全部答案,可以到我的CSDN资源页下载.
文末诗词子规夜半犹啼血,不信东风唤不回。——王令《送春》参考文献[1]图灵停机问题(haltingproblem).https://blog.csdn.net/MyLinChi/article/details/79044156[2]传教士野人过河问题.https://blog.csdn.net/aidayei/article/details/6768696[3]α-β剪枝算法.https://blog.csdn.net/luningcsdn/article/details/50930276[4]八数码问题.https://www.cnblogs.com/guanghe/p/5485816.html
人工智能期末试题及答案
一单项选择题(每小题2分,共10分)1.首次提出“人工智能”是在(D)年
A.1946 B.1960 C.1916 D.1956
2.人工智能应用研究的两个最重要最广泛领域为:B
A.专家系统、自动规划 B.专家系统、机器学习
C.机器学习、智能控制 D.机器学习、自然语言理解
3.下列不是知识表示法的是 A 。
A:计算机表示法 B:“与/或”图表示法
C:状态空间表示法 D:产生式规则表示法
4.下列关于不确定性知识描述错误的是 C 。
A:不确定性知识是不可以精确表示的
B:专家知识通常属于不确定性知识
C:不确定性知识是经过处理过的知识
D:不确定性知识的事实与结论的关系不是简单的“是”或“不是”。
5.下图是一个迷宫,S0是入口,Sg是出口,把入口作为初始节点,出口作为目标节点,通道作为分支,画出从入口S0出发,寻找出口Sg的状态树。根据深度优先搜索方法搜索的路径是 C 。
A:s0-s4-s5-s6-s9-sg B:s0-s4-s1-s2-s3-s6-s9-sg
C:s0-s4-s1-s2-s3-s5-s6-s8-s9-sg D:s0-s4-s7-s5-s6-s9-sg
二 填空题(每空2分,共20分)1.目前人工智能的主要学派有三家:符号主义、 进化主义 和 连接主义 。
2.问题的状态空间包含三种说明的集合, 初始状态集合S、操作符集合F以及目标状态集合G。
3、启发式搜索中,利用一些线索来帮助足迹选择搜索方向,这些线索称为 启发式(Heuristic)信息。
4、计算智能是人工智能研究的新内容,涉及 神经计算、模糊计算和 进化计算等。
5、不确定性推理主要有两种不确定性,即关于 结论的不确定性和关于 证据的不确定性。
三名称解释(每词4分,共20分)人工智能 专家系统 遗传算法 机器学习 数据挖掘
答:
(1)人工智能
人工智能(ArtificialIntelligence),英文缩写为AI。它是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。 人工智能是计算机科学的一个分支,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器,该领域的研究包括机器人、语言识别、图像识别、自然语言处理和专家系统等
(2)专家系统
专家系统是一个含有大量的某个领域专家水平的知识与经验智能计算机程序系统,能够利用人类专家的知识和解决问题的方法来处理该领域问题.简而言之,专家系统是一种模拟人类专家解决领域问题的计算机程序系统
(3)遗传算法
遗传算法是一种以“电子束搜索”特点抑制搜索空间的计算量爆炸的搜索方法,它能以解空间的多点充分搜索,运用基因算法,反复交叉,以突变方式的操作,模拟事物内部多样性和对环境变化的高度适应性,其特点是操作性强,并能同时避免陷入局部极小点,使问题快速地全局收敛,是一类能将多个信息全局利用的自律分散系统。运用遗传算法(GA)等进化方法制成的可进化硬件(EHW),可产生超出现有模型的技术综合及设计者能力的新颖电路,特别是GA独特的全局优化性能,使其自学习、自适应、自组织、自进化能力获得更充分的发挥,为在无人空间场所进行自动综合、扩展大规模并行处理(MPP)以及实时、灵活地配置、调用基于EPGA的函数级EHW,解决多维空间中不确定性的复杂问题开通了航向
(4)机器学习
机器学习(MachineLearning)是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。它是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域,它主要使用归纳、综合而不是演绎
(5)数据挖掘
数据挖掘是指从数据集合中自动抽取隐藏在数据中的那些有用信息的非平凡过程,这些信息的表现形式为:规则、概念、规律及模式等。它可帮助决策者分析历史数据及当前数据,并从中发现隐藏的关系和模式,进而预测未来可能发生的行为。数据挖掘的过程也叫知识发现的过程。
四 简答题(每小题5分,共30分)1. 人工智能有哪些研究领域和应用领域?
答:(1)研究领域
自然语言处理,知识表现,智能搜索,推理,规划,机器学习,知识获取,组合调度问题,感知问题,模式识别,逻辑程序设计,软计算,不精确和不确定的管理,人工生命,神经网络,复杂系统,遗传算法
(2)应用领域
智能控制,机器人学,语言和图像理解,遗传编程
2. 简述模式识别的基本过程
答:(1)信息获取
(2)预处理:对获取信号进行规范化等各种处理(3)特征提取与选择:将识别样本构造成便于比较、分析的描述量即特征向量(4)分类器设计:由训练过程将训练样本提供的信息变为判别事物的判别函数(5)分类决策:对样本特征分量按判别函数的计算结果进行分类
3.状态空间法、谓词逻辑法和语义网络的要点分别是什么?
答:(1)状态空间法是以状态和算符为基础来表示和求解问题的,三个要点是:状态,算符,问题的状态空间
(2)谓词逻辑法要点:命题真值,论域与谓词,连接词和量词,项与合式公式,自由变元和约束变元
(3)语义网络要点:类属关系,包含关系,属性关系,时间关系,位置关系,相近关系,推论关系
4.简述Agent的定义和基本特征
答:(1)Agent定义:Agent指的是一种实体,而且是一种具有智能的实体。这种实体可以是智能软件、智能设备、智能机器人或智能计算机系统等等,甚至也可以是人
(2)Agent基本特征:
a.自主性
Agent具有属于其自身的计算资源和局部于自身的行为控制机制,能够在没有外界直接操纵的情况下,根据其内部状态和感知到的环境信息,决定和控制自身的行为。例如,SNMP中的agent就是独立运行在被管理单元上的自主进程。
b.交互性
Agent能够与其他Agent(包括人),用Agent通信语言实施灵活多样的交互,能够有效地与其他Agent协同工作。例如,一个Internet上的用户需要使用Agent通信语言向主动服务Agent陈述信息需求。
c.反应性
Agent能够感知所处的环境(可能是物理世界,操纵图形界面的用户,或其他Agent等),并对相关事件作出适时反应。例如,一个模拟飞机的Agent能够对用户的操纵作出适时反应。
d.主动性
Agent能够遵循承诺采取主动行动,表现出面向目标的行为。例如,一个Internet上的主动服务Agent,在获得新的信息之后能够按照约定主动将其提交给需要的用户;一个工作流管理Agent,能够按照约定将最新的工作进展情况主动通报给有关的工作站
5. 根据自己的理解给出人工神经网络的定义,并指出其特征。
答:(1)人工神经网络是一种应用类似于大脑神经突触联接的结构进行信息处理的数学模型 (2)特征:a.非线性非线性关系是自然界的普遍特性。大脑智慧就是一种非线性现象。人工神经元处于激活或抑制二种不同的状态,这种行为在数学上表现为一种非线性 关系。具有阈值的神经元构成的网络具有更好的性能,可以提高容错性和存储量
b.非局限性一个神经网络通常由多个神经元广泛连接而成。一个系统的整体行为不仅取决于单个神经元的特征,而且可能主要由单元之间的相互作用、相互连接所决定。通过单元之间的大量连接模拟大脑的非局限性。联想记忆是非局限性的典型例子
c.非常定性人工神经网络具有自适应、自组织、自学习能力。神经网络不但处理的信息可以有各种变化,而且在处理信息的同时,非线性动力系统本身也在不断变化。经常采用迭代过程描写动力系统的演化过程
d.非凸性一个系统的演化方向,在一定条件下将取决于某个特定的状态函数。例如能量函数,它的极值相应于系统比较稳定的状态。非凸性是指这种函数有多个极值,故系统具有多个较稳定的平衡态,这将导致系统演化的多样性
6. 有一个农夫带一只狐狸、一只小羊和一篮菜过河。假设农夫每次只能带一样东西过河,考虑安全,无农夫看管时,狐狸和小羊不能在一起,小羊和菜篮不能在一起。试设计求解该问题的状态空间,并画出状态空间图。
答:以变量m、f、s、v分别指示农夫、狐狸、小羊、菜,且每个变量只可取值1(表示在左岸)或0(表示在右岸)。问题状态可以四元组(m、f、s、v)描述,设初始状态下均在左岸,目标状态下都到达右岸。从而,问题求解任务可描述为(1,1,1,1)->(0,0,0,0)
由于问题简单,状态空间中可能的状态总数为2×2×2×2=16,由于要遵从安全限制,合法的状态只有(除初、目状态外): 1110,1101,1011,1010,0101,0001,0010,0100;不合法状态有:0111,1000,1100,0011,0110,1001
设计二类操作算子:Lx、Rx,x为m、f、s、v时分别指示农夫独自,带狐狸,带小羊,带菜过河;状态空间图如下所示.由于Lx和Rx是互逆操作,故而解答路径可有无数条,但最近的只有二条;都是7个操作步
五.综述题(20分)1.(本题10分)对于八数码难题按下式定义估价函数:
f(x)=d(x)+h(x)
其中,d(x)为节点x的深度;h(x)是所有棋子偏离目标位置的曼哈顿距离(棋子偏离目标位置的水平距离和垂直距离和),例如下图所示的初始状态S0:8的曼哈顿距离为2;2的曼哈顿距离为1;1的曼哈顿距离为1;6的曼哈顿距离为1;h(S0)=5。
(1)用A*搜索法搜索目标,列出头三步搜索中的OPEN、CLOSED表的内容和当前扩展节点的f值。
(2)画出搜索树和当前扩展节点的f值。
解:(1)如下表
(2)搜索树如下图,右上角的数字是其估价函数值
2.(本题10)您认为《人工智能》课程的哪一部分内容对您的毕业设计或者您以后的工作特别有用?如果有,请叙述其原理;如果没有,请您谈谈人工智能的发展对人类有哪些的影响?
答:我认为人工智能的发展对人类的影响主要有以下五个方面
(1)劳务就业问题。由于人工智能能够代替人类进行各种脑力劳动,例如用专家系统代替管理人员或医生进行决策或诊断与治疗病人疾病,所以,将会使一部分人不得不改变他们的工种,甚至造成失业。人工智能在科技和工程中的应用,会使一些人失去介入信息处理活动(如规划、诊断、理解和决策等)的机会,甚至不得不改变自己的工作方式。
(2)社会结构变化。人们一方面希望人工智能和智能机器能够代替人类从事各种劳动,另一方面又担心它们的发展会引起新的社会问题。实际上,近十多年来,社会结构正在发生一种静悄悄的变化。
(3)思维方式与观念的变化。人工智能的发展与推广应用,将影响到人类的思维方式和传统观念,并使它们发生改变。过分地依赖计算机的建议而不加分析地接受,将会使智能机器用户的认知能力下降,并增加误解。
(4)心理上的威胁。人工智能还使一部分社会成员感到心理上的威胁,或叫做精神威胁。人们一般认为,只有人类才具有感知精神,而且以此与机器相别。如果有一天,这些人开始相信机器也能够思维和创作,那么他们可能会感到失望,甚至感到威胁。他们担心:有朝一日,智能机器的人工智能会超过人类的自然智能,使人类沦为智能机器和智能系统的奴隶。
(5)技术失控的危险。任何新技术最大危险莫过于人类对它失去了控制,或者是它落入那些企图利用新技术反对人类的人手中